En kjekk Kotlin-funksjon som logger trege SQL-er
Coroutines er kraftige saker! Her er historien om funksjonen som kan pakke inn SQL-er (og hva som helst async, egentlig), og roper ut om spørringen tok lengere tid enn 10 sekunder.
Null hull
Alle error-logger i systemet vårt poster en melding til en Slack-kanal.
Hvordan unngår vi at hele gjengen får alarm fatigue?
Vi kjører en policy vi kaller "null hull". Det vil si at alle feil skal håndteres på et eller annet vis, og at alle exceptions og error-logger skal være "på ordentlig".
I starten var det en god del edge caser hvor vi fikk uhåndterte feil om enkelte input-felter var tomme i GUI-et eller om en ekstern tjeneste timet ut men bare ble retryet. Vi tettet disse hullene én etter én, og nå er vi i en situasjon hvor feil i prod betyr at noe faktisk er feil.
Feil er feil, og trege SQL-er er feil
Vi utvidet "null hull" til å gjelde trege SQL-er også. Vi har egentlig ingen SQL-er som bør ta noe særlig mere enn 2-300 millisekunder. Bare for å starte et sted, og siden P99-latency er en ting og vi tross alt kjører i clouden, satt vi grensa på 10 sekunder.
Alle spørringer som ikke er ferdige etter 10 sekunder, skal logge en feil.
Målet: Pakke inn med måling
Målet var å kunne ta kode som gjør SQL-er:
dbSess.list(queryOf("SELECT ..."))
og pakke dem inn i en helper-funksjon som ikke gjør noe annet enn å legge på error-logging:
logSlowQueries {
dbSess.list(queryOf("SELECT ..."))
}
Middelet: Funksjonen som bruker alle triks i boka
Her er funksjonen vi snekret sammen.
suspend fun <T> logSlowQueries(
block: suspend () -> T
): T = coroutineScope {
val loggerTask = launch {
delay(Duration.ofSeconds(10))
val otel = Span.current().spanContext
if (otel.isValid) {
log.error("Slow query! traceId=${otel.traceId}")
} else {
log.error("Slow query! NO OTEL CTX AVAILABLE")
}
}
try {
block()
} finally {
loggerTask.cancel()
}
}
Denne funksjonen bruker så godt som alle triksene i Kotlin-boka.
(Og med "alle triks i boka", mener jeg selvfølgelig denne boka 😇)
Funksjonen lager et coroutine scope. Det er den nødt til for å kunne gjøre alle de asynkrone snurrepipperiene vi trenger for å få til loggingen.
Funksjonen er også en higher order function. Det vil si at det er en funksjon som tar imot en annen funksjon - block.
Funksjonen bruker generics. Vi bryr os ikke om hva block returnerer, bare at returverdien fra funksjonen vår er det samme som block. Det betyr i praksis at vi kan wrappe hvilken kode vi vil med logSlowQueries uten å måtte gjøre sit-ups i typesystemet. I funksjonell programmering med typer kommer man omtrent ikke unna generics i kodebasen, i og med at man ikke har abstrakte klasser og arv i verktøykassa si.
I et coroutine scope finnes launch. Dette er en liten helper som starter et nytt coroutine scope igjen. Koden inne i launch kjører umiddelbart, men asynkront, uten å gå i beina på koden som kommer etter.
Det første loggerTask gjør, er å bruke delay til å vente i 10 sekunder. I motsetning til Thread.sleep som holder på en hel JVM-tråd, snakker delay med Kotlin sitt coroutine-maskineri og lar den håndtere trådene. I praksis blir jobben satt på pause, og etter det har gått sånn ca. 10 sekunder (basert på en scheduled thread pool executor), blir jobben fortsatt. Eller continued, om du vil. Dette er sånn "coroutines" har fått navnet sitt, siden de er basert på continuations under panseret.
Duration er en super liten greie på JVM-en som lar deg representere tidsverdier som hakket mindre magiske tall. Duration.ofSeconds(10) leser mye bedre enn 10000. Dessuten er den helt fri for en antagelse om hva basis-enheten for tid er, som jo kan være litt forvirrende noen ganger. (Er det sekunder? Millisekunder? Noe annet?)
Så må vi jo kalle block - det er der SQL-en faktisk kjører.
Når block har kjørt ferdig, kaller vi cancel() på loggerTask. Det betyr at én av to ting skjer:
- Enten står
loggerTaskog venter pådelay. Dermed avbrytes den før den rekker å komme seg helt til loggingen. - Eller så har spørringen tatt så lang tid at
loggerTaskhar blitt ferdig, har logget og pinget Slack-kanalen vår, og da gjørcancel()i praksis ingenting.
Funksjonen i bruk
Her er et eksempel på hvordan denne funksjonen kalles om du for eksempel bruker Kotliquery til å kjøre SQL-ene dine, som vi gjør.
import javax.sql.DataSource
import kotliquery.sessionOf
import kotliquery.queryOf
suspend fun myBusinessLogicThingie(
dataSource: DataSource
): List<MyBusinessObject> {
logSlowQueries {
sessionOf(dataSource).use { session ->
session.list(queryOf("SELECT ..."))
}
}
}
I praksis har vi puttet logSlowQueries i helper-funksjoner vi har for å instrumentere og sette opp Kotliquery-sessions med diverse defaults for timeouts, strict mode, osv.
Konteksten til coroutine context
Et problem med å logge i en launch inne i en coroutineContext, er at når loggerTask kjører, har den null anelse om hvilken SQL som faktisk blir kjørt. Den har ikke engang tilgang på stacken hvor SQL-en kjører, i og med at coroutine-kode kjører i Kotlin sine thread pools og orkestreringsmaskineri for asynkronitet og samtidighet.
Så det går ikke an å bare fiske ut Thread.currentThread().stackTrace eller noe i den duren.
Men det hadde jo vært litt kjekt om Slack-kanalen vår sa hvilken SQL som går tregt, ikke bare at en SQL går tregt.
Open Telemetry redder dagen
Heldigvis har vi instrumentert koden vår med OpenTelemetry! Ved å inkluderer Open Telemetry sin traceId og spanId, får vi all konteksten vi trenger for å finne igjen feilen fra loggmeldinga.
log.error("Slow query! traceId=${otel.traceId}")
I loggen blir dette seendes omtrent sånn ut:
2025-08-04 16:27:54,291 [DefaultDispatcher-worker-8]
ERROR snowbee.homeless.DbUtils
Slow query! traceId=7ab39842f4af2662feec8d3a63d32aa4
Dermed kan vi bare søke opp trace 7ab39842f4af2662feec8d3a63d32aa4 i Honeycomb hvor vi poster all telemetrien vår, og se nøyaktig hvilken kontekst den trege spørringen kjørte i.
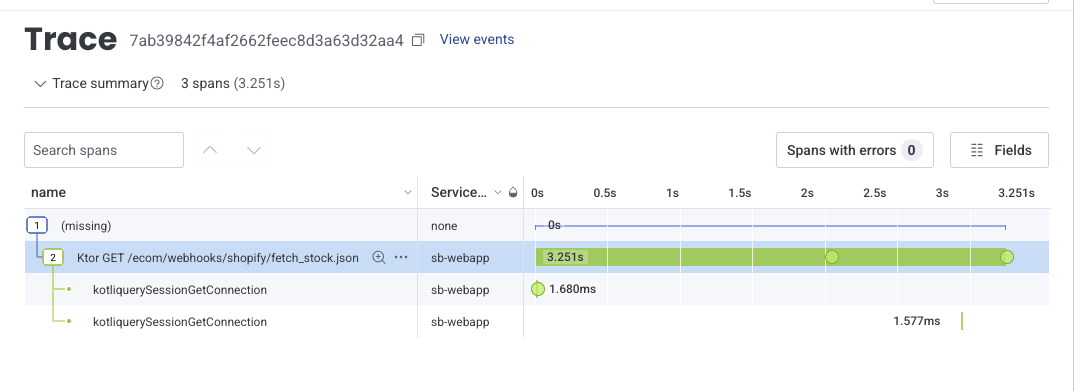
Ikke overraskende, tok spørringen vår som henter ut fullstendig lagerstatus for alle produkter i en nettbutikk litt mere tid enn snittspørringen i systemet.
(Og hvis den observante leser legger kanskje merke til at telemetrien sier at spørringen tok 3.251 sekunder. Her hadde vi satt varseltiden til 2 sekunder, for å teste litt hvordan det oppførte seg i praksis.)